Share
Machine Learning in Image Processing | Tools & Applications

- BLOG
- Artificial Intelligence
- January 31, 2026
Images are simple things to most, but building systems that can interpret them is rarely simple. A slight change in lighting, camera angle, background, or image quality can cause rule-based image processing to fail or produce inconsistent results.
That’s why machine learning in image processing has become the practical solution for modern visual tasks. Instead of relying on fixed thresholds and handcrafted rules, ML models learn patterns from real image data, which helps them recognize objects, detect defects, and enhance images more reliably in real-world conditions.
In this blog, we’ll explain what machine learning in image processing really is. We will also discuss why traditional approaches struggle at scale, how ML fits into the workflow, and which models and tools power it.
Contents
- 1 What Machine Learning in Image Processing Actually Solves
- 2 Traditional Image Processing vs Machine Learning Approaches
- 2.1 Rule-Based Logic vs Learned Representations
- 2.2 Manual Features vs Automatic Feature Learning
- 2.3 Fixed Pipelines vs Flexible Model Workflows
- 2.4 Sensitivity to Noise and Lighting vs Learned Invariance
- 2.5 Difficulty Scaling Rules vs Scalability Through Training
- 2.6 Domain Expertise vs Data-Driven Learning Effort
- 2.7 Maintenance Burden vs Retraining Flexibility
- 2.8 Interpretability of Rules vs Model Black-Box
- 2.9 Basic Tasks vs Complex Recognition Tasks
- 2.10 Denoising and Enhancement: Filters vs Learned Models
- 2.11 High-Resolution Detail: Interpolation vs Neural Upscaling
- 2.12 Industry Adoption: Controlled vs Real-World Production
- 2.13 Automation at Scale: Manual Rules vs AI-Driven Analysis
- 2.14 Core Architecture: Descriptors vs Convolutional Networks
- 3 Turn real-world images into real business decisions with Webisoft.
- 4 How Machine Learning Fits Into the Image Processing Workflow
- 5 Machine Learning Models Used in Image Processing
- 5.1 Convolutional Neural Networks (CNNs)
- 5.2 Image Classification Models
- 5.3 Object Detection Models (YOLO, Faster R-CNN)
- 5.4 Segmentation Models (U-Net, Mask R-CNN)
- 5.5 Recognition and Embedding Models
- 5.6 Pose Estimation and Landmark Models
- 5.7 Super-resolution and Restoration models
- 5.8 Practical Pipeline
- 6 Tools and Frameworks Used in Machine Learning Image Processing
- 7 Real-World Applications of Machine Learning in Image Processing
- 8 Challenges and Limitations of Machine Learning in Image Processing
- 9 How Webisoft Mitigates These Challenges
- 9.1 Data Quality and Label Governance
- 9.2 Smarter Training With Transfer Learning
- 9.3 Robust Preprocessing for Noisy and Low-Quality Images
- 9.4 Generalization Controls to Reduce Overfitting
- 9.5 Cost Optimization With Efficient Model Architectures
- 9.6 Edge and Cloud Deployment Strategy for Scale
- 9.7 Explainability Layer for High-Stakes Decisions
- 9.8 Bias Checks and Fairness Testing
- 9.9 Security Hardening Against Adversarial Inputs
- 9.10 Continuous Monitoring and Retraining for Drift Control
- 10 Turn real-world images into real business decisions with Webisoft.
- 11 Conclusion
- 12 FAQs
What Machine Learning in Image Processing Actually Solves
Machine learning in image processing solves one main problem: images don’t follow fixed rules. A photo is not like a form field or a database row. It changes every time you change the camera, lighting, angle, or distance. Rule-based image processing breaks because it needs perfect conditions.
You can write rules for “bright image,” “clear edges,” or “fixed background,” but real images rarely behave that cleanly. Even a simple shadow can confuse the system and flip the result. That’s why visual variability becomes the core issue.
The same object can look completely different across photos because of blur, motion, glare, low light, or partial occlusion. So the rules don’t just fail sometimes, they fail often. Machine learning for image processing avoids that trap by learning patterns instead of relying on hand-written conditions.
You show the model many examples, and it learns what matters visually, like shape, texture, and spatial structure. This makes image processing using machine learning far more stable when images change. Here’s a grounded example. Suppose you want to detect dogs in phone photos.
A rule-based system might look for “two sharp ears” and “a tail,” but it fails when the dog turns sideways or gets cropped. Computer vision machine learning learns from thousands of dog images, so it still detects the dog even when the photo looks messy.
Traditional Image Processing vs Machine Learning Approaches
 Traditional image processing and machine learning solve image problems in two very different ways. This difference matters because production images rarely stay “clean.” Lighting changes, cameras vary, objects rotate, and noise creeps in. So choosing between rule-based vision and learning-based vision directly impacts accuracy, cost, and long-term maintenance:
Traditional image processing and machine learning solve image problems in two very different ways. This difference matters because production images rarely stay “clean.” Lighting changes, cameras vary, objects rotate, and noise creeps in. So choosing between rule-based vision and learning-based vision directly impacts accuracy, cost, and long-term maintenance:
Rule-Based Logic vs Learned Representations
Traditional image processing relies on handcrafted operations like thresholding, filters, and edge detection to process visual data. These handcrafted steps work well only when the scene stays simple and predictable, because each rule assumes specific image behavior. Machine learning in image processing learns patterns directly from large datasets, allowing it to handle complex, variable scenes that fixed rules struggle with.
Manual Features vs Automatic Feature Learning
Traditional systems use manually designed features such as HOG, SIFT, or specific thresholds that are tuned by experts for each task. These features lose effectiveness when images vary in lighting, pose, or background because they don’t generalize beyond what’s been explicitly defined. Machine learning for image processing learns hierarchical features from raw pixel data, enabling it to recognize patterns across diverse conditions.
Fixed Pipelines vs Flexible Model Workflows
Traditional pipelines process images as a strict sequence of steps, so a failure in one stage cascades through the whole system. This rigidity makes them fragile in real-world scenarios like CCTV surveillance or uncontrolled lighting environments. Image processing using machine learning integrates feature learning and decision making, so it stays robust even when inputs change unexpectedly.
Sensitivity to Noise and Lighting vs Learned Invariance
Traditional vision systems crack when images contain noise, blur, or sharp lighting shifts because rules depend on stable pixel patterns. Studies show that real image quality degradations such as illumination changes and blur significantly reduce performance for rule-based methods. Computer vision machine learning, by contrast, learns invariances, patterns that remain consistent despite noise, lighting changes, or scale variations.
Difficulty Scaling Rules vs Scalability Through Training
Traditional approaches require engineers to retune thresholds and logic for every new camera, dataset, or environment, which becomes costly at scale. In multi-camera surveillance or automated manufacturing, maintaining these rules becomes a bottleneck. ML in image processing scales more easily by retraining models on diverse data rather than rewriting rules for each new setting.
Domain Expertise vs Data-Driven Learning Effort
Traditional workflows demand heavy domain expertise to design, debug, and tune feature extractors and rule sets. This makes early setup slow and expensive, especially on complex tasks like multi-object detection or irregular shapes.
Image classification using machine learning shifts effort from handcrafting rules to building and labeling datasets, which often yields better performance when data is abundant.
Maintenance Burden vs Retraining Flexibility
Traditional systems require manual rule updates whenever the task or imaging conditions change, leading to ongoing maintenance work. Frequent rule revisions make deployment across many devices or environments labor-intensive. Image recognition using machine learning reduces this by refining a central model with new training data instead of rewriting logic. 
Interpretability of Rules vs Model Black-Box
Traditional methods are transparent in how decisions are made because every filter or rule has clear semantics. This makes debugging easier but limits adaptability when rules don’t cover new image conditions. Object detection using machine learning trades some interpretability for high performance, and practitioners use validation metrics and explainability tools to gauge model behavior.
Basic Tasks vs Complex Recognition Tasks
Traditional techniques excel at simple, structured tasks like edge detection or fixed template matching and remain relevant in certain industrial uses. However, research shows deep learning methods outperform classical pipelines on tasks like classification and segmentation because they capture deeper visual structure. That’s why image segmentation using machine learning and advanced recognition is dominant in modern systems.
Denoising and Enhancement: Filters vs Learned Models
Traditional denoising applies filters such as median or Gaussian blur, which often smooth out noise at the cost of detail. Deep learning models learn to remove noise while preserving important structures, leading to better results in real imagery.
Approaches using image denoising using machine learning and noise reduction using machine learning achieve higher fidelity than classical filters in many benchmarks.
High-Resolution Detail: Interpolation vs Neural Upscaling
Traditional upscaling methods use interpolation, which just stretches pixels and creates blur. Deep architectures learn how high-resolution details actually look, enabling super resolution using deep learning that reconstructs fine texture and sharp edges. This difference is why learned upscalers often outperform traditional interpolation in visual quality.
Industry Adoption: Controlled vs Real-World Production
Traditional vision fits well in controlled factory environments with fixed angles and lighting. In contrast, real environments like autonomous driving, aerial imagery, and medical imaging show extreme variation, making rule pipelines unreliable. Research confirms that computer vision machine learning approaches are widely adopted in real production systems because they generalize better and handle complex visual patterns.
Automation at Scale: Manual Rules vs AI-Driven Analysis
Rule systems often need human review for edge cases, limiting throughput. Automated image analysis using AI uses learned models to make consistent decisions across huge volumes of images without constant manual oversight. This automation advantage explains why large-scale image analytics increasingly uses learning-based systems.
Core Architecture: Descriptors vs Convolutional Networks
Traditional vision pipelines depend on filters and descriptors tailored by experts, which can miss subtle contextual cues. Convolutional neural networks like LeNet and AlexNet showed that learned hierarchical features dramatically improve performance on large visual datasets.
This structural shift underpins why approaches like CNN for image processing and convolutional neural networks for image processing dominate modern vision research. If you’re deciding between a rule-based pipeline and an ML-based approach, the real question is what your images look like in production.
Webisoft helps you evaluate that reality, then builds the right solution. So you get a vision system that stays accurate under real lighting, noise, and scale changes, without turning maintenance into a long-term burden.


Turn real-world images into real business decisions with Webisoft.
Book a free consultation – Get a production-ready ML vision system built for accuracy, speed, and long-term stability.
How Machine Learning Fits Into the Image Processing Workflow
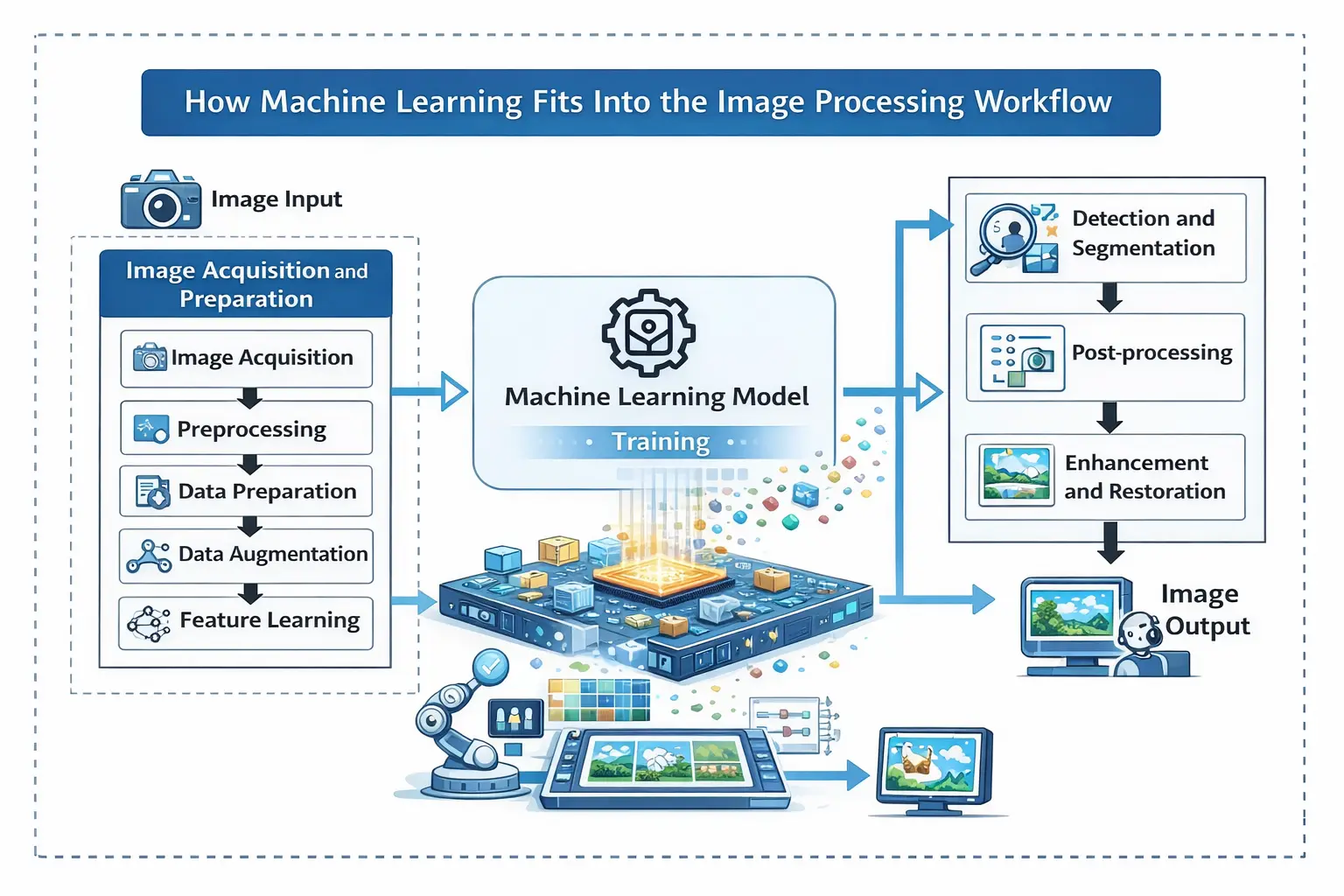 Machine learning fits into image processing as the “decision layer” that turns pixels into meaning. Traditional image processing cleans and prepares the image, while ML handles tasks like recognition, detection, and segmentation. This is why machine learning in image processing shows up in most modern production workflows.
Machine learning fits into image processing as the “decision layer” that turns pixels into meaning. Traditional image processing cleans and prepares the image, while ML handles tasks like recognition, detection, and segmentation. This is why machine learning in image processing shows up in most modern production workflows.
Image Acquisition
Image processing begins when a camera, scanner, drone, or sensor captures raw images. These images often contain blur, glare, and compression artifacts, especially in CCTV or mobile camera feeds. So teams treat acquisition as a quality step, not just “taking a photo.”
Preprocessing
Preprocessing fixes problems that confuse models, like uneven brightness or random noise. Teams resize images, normalize colors, and apply noise reduction using machine learning or classic filters depending on the use case. This step makes training stable and improves prediction accuracy.
Data Preparation
ML needs a large set of examples that match real-world conditions. Teams label objects, defects, or body parts, then build datasets that include different lighting, angles, and backgrounds. This is where machine learning for image processing becomes a data job, not only a coding job.
Data Augmentation
Data augmentation increases dataset size by flipping, rotating, zooming, and cropping images. This teaches models to handle real camera changes without breaking. It is a standard step in computer vision machine learning pipelines.
Feature Learning
Traditional systems rely on feature extraction in image processing like edges, corners, or textures chosen by engineers. ML replaces that with learned features using CNN for image processing, where early layers learn edges and later layers learn object parts. This is why deep learning in image processing scales better than handcrafted rules.
Training
Training is where the model learns patterns by comparing predictions to ground truth labels. For classification tasks, the output is a label like “defective” or “not defective,” which is image classification using machine learning. For identity matching or search, teams rely on embeddings for image recognition using machine learning.
Detection and Segmentation
Detection answers what the object is and where it appears in the image. That is why factories and traffic systems use object detection using machine learning for boxes around defects, vehicles, or products. Segmentation goes deeper and labels pixels, which makes image segmentation using machine learning essential for medical scans and satellite imagery.
Post-processing
Post-processing turns model output into a final business decision. Teams apply confidence thresholds, remove duplicates, smooth boundaries, and generate overlays or reports. This is the step that converts predictions into automated image analysis using AI that teams can trust.
Enhancement and Restoration
Many production images arrive low-quality, especially in surveillance and healthcare. Teams use image denoising using machine learning to clean grainy images and image enhancement using machine learning to recover clarity without losing edges. For low-resolution inputs, super resolution using deep learning improves detail before analysis.
Machine Learning Models Used in Image Processing
 Machine learning models in image processing mainly differ by what they “see” and what they output. Some models output a label, some output boxes, and others output pixel-level masks. This is why choosing the right model matters as much as choosing the right dataset.
Machine learning models in image processing mainly differ by what they “see” and what they output. Some models output a label, some output boxes, and others output pixel-level masks. This is why choosing the right model matters as much as choosing the right dataset.
Convolutional Neural Networks (CNNs)
CNNs power most modern vision systems because they learn visual patterns directly from pixels. They learn simple edges first, then textures, then object parts, which makes them ideal for real images. That’s why convolutional neural networks for image processing remain the backbone of modern deep learning in image processing.
Image Classification Models
Classification models answer one question: “What is in this image?” This is the base of image classification using machine learning, like labeling an X-ray as “normal” or “abnormal,” or sorting products as “correct” vs “defective.” Companies use this for quality checks, medical triage, and content moderation.
Object Detection Models (YOLO, Faster R-CNN)
Detection models answer: “What is in the image and where is it?” That’s why object detection using machine learning is used in traffic monitoring, warehouse automation, and retail shelf tracking. YOLO-style models became popular because they can run fast enough for real-time systems.
Segmentation Models (U-Net, Mask R-CNN)
Segmentation models label every pixel, so they don’t just find an object, they outline it. This is the core of image segmentation using machine learning, especially for tumors, organs, roads, or cracks on surfaces. Hospitals use U-Net-style models because they work well on medical scans with soft boundaries.
Recognition and Embedding Models
Recognition models learn a compact “signature” of an image or face. This powers image recognition using machine learning, like face unlock, duplicate product matching, or searching visually similar items. This approach works well because embeddings stay stable even when lighting and angles change.
Pose Estimation and Landmark Models
Pose models detect key points like joints, facial landmarks, or body alignment. These models support sports analytics, physical therapy apps, and driver monitoring systems. Teams use them because key points give structured data that is easier to measure than raw pixels.
Super-resolution and Restoration models
Restoration models improve images before analysis. This includes image denoising using machine learning, image enhancement using machine learning, and super resolution using deep learning for sharper details. These models matter in surveillance and medical imaging where poor input quality can destroy downstream accuracy.
Practical Pipeline
Real systems combine multiple models into a workflow. A camera feed may run denoising first, then detection, then segmentation, then classification. That end-to-end setup enables automated image analysis using AI in manufacturing lines, hospitals, and smart city systems.
Tools and Frameworks Used in Machine Learning Image Processing
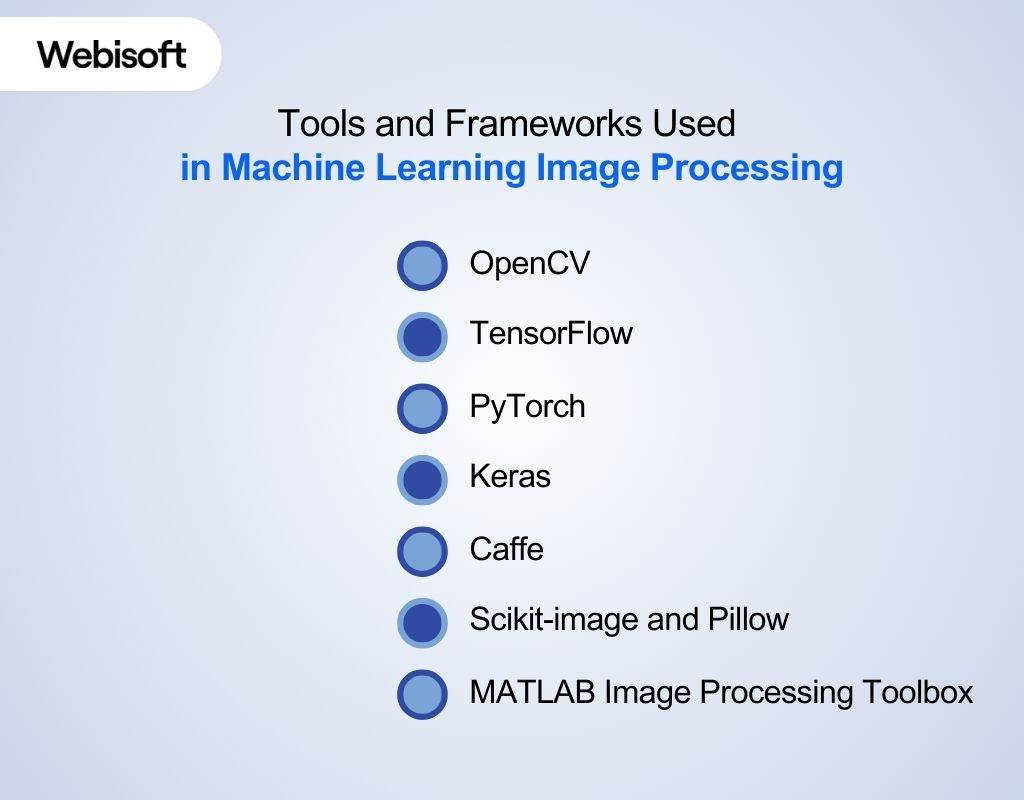 Tools matter in ML image processing because they decide how fast you can build, train, test, and deploy models. Some tools help you clean and transform images, while others help you train deep models on GPUs. So the best stack usually mixes computer vision libraries with deep learning frameworks.
Tools matter in ML image processing because they decide how fast you can build, train, test, and deploy models. Some tools help you clean and transform images, while others help you train deep models on GPUs. So the best stack usually mixes computer vision libraries with deep learning frameworks.
OpenCV
OpenCV helps you handle images before training even starts. It supports resizing, cropping, filtering, compression, and many classic operations used in real pipelines. Teams rely on it heavily in AI image processing because it makes data cleanup fast and repeatable.
TensorFlow
TensorFlow supports large-scale training and deployment across cloud, mobile, and edge devices. It fits well when teams need stable pipelines and production tools like TensorFlow Lite and TFX. Many companies choose it for image processing using machine learning when deployment matters as much as model accuracy.
PyTorch
PyTorch helps teams move fast from prototype to working model. It supports dynamic model building, distributed training, and strong GPU support, which makes it popular in research and product teams. It is a common choice for machine learning for image processing when custom architectures and experimentation matter.
Keras
Keras simplifies deep learning by offering a high-level API that reduces boilerplate code. It helps beginners and teams who want quick experiments without deep framework complexity. Many developers use it for fast training of CNN for image processing models.
Caffe
Caffe was built for speed and modular CNN design, mainly for classification and segmentation tasks. It supports CPU/GPU switching and efficient model configuration. Some legacy systems still run convolutional neural networks for image processing using Caffe-based pipelines.
Scikit-image and Pillow
Scikit-image offers algorithms for transformations, segmentation, and filtering in a clean Python interface. Pillow helps with basic image loading, saving, format conversion, and lightweight edits. These tools often support feature extraction in image processing during dataset preparation.
MATLAB Image Processing Toolbox
MATLAB tools help teams prototype workflows quickly, especially in engineering and academic environments. It supports segmentation, registration, batch processing, and even 3D workflows. Teams often use it in regulated industries before moving models into production stacks.
Real-World Applications of Machine Learning in Image Processing
 Machine learning has moved from research labs into real systems because it can handle huge amounts of visual data accurately and quickly. The global market for machine learning technologies, including ML in image applications, is growing rapidly and is expected to exceed $192 billion by 2025, showing strong industry adoption across sectors.
Machine learning has moved from research labs into real systems because it can handle huge amounts of visual data accurately and quickly. The global market for machine learning technologies, including ML in image applications, is growing rapidly and is expected to exceed $192 billion by 2025, showing strong industry adoption across sectors.
Medical imaging diagnostics
Healthcare uses machine learning for image processing to analyze X-rays, CT scans, and MRIs to spot diseases like cancer, fractures, and organ abnormalities. In practice, deep learning systems now perform tasks such as tumor segmentation and disease prediction with accuracy levels approaching clinical usability, making diagnostic workflows faster and more reliable.
Autonomous vehicles
Self-driving cars rely on image recognition using machine learning and object detection using machine learning to detect lanes, pedestrians, traffic lights, and obstacles while driving. Research shows that these perception systems can achieve over 98% accuracy in identifying and classifying road elements, enabling safer navigation.
Security and surveillance
Security and surveillance systems use AI image processing to recognize faces, detect unauthorized entry, and identify suspicious objects across multiple camera feeds. This automation reduces false negatives and improves response times because ML models scan every frame without fatigue — something humans cannot match in volume or consistency.
Manufacturing quality control
Factories increasingly use automated image analysis using AI to inspect products on production lines for defects like scratches, misalignments, or missing parts. With ML systems, manufacturers reduce waste and increase throughput because visual inspection becomes continuous and objective across all units produced.
Retail and e-commerce
Retail platforms implement image processing using machine learning to power visual search — letting customers upload a picture to find similar products automatically. These systems improve user engagement and conversion because they understand product appearance beyond text tags alone, blending classification and similarity search at scale.
Robotics and machine vision
Robots use computer vision machine learning to understand shapes, sizes, and object positions before acting, especially when tactile sensors fail. In smart logistics and sorting systems, this visual understanding enables robots to handle varied objects efficiently, boosting automation accuracy.
Video analytics
Video streams are treated as rapid sequences of images, and ML models analyze them to detect events like traffic incidents, crowd flow changes, or safety hazards in real time. Such deployments improve public safety and operational awareness in transportation hubs and large venues because the system processes each frame rapidly and consistently.
Agriculture and environment
Drones and satellites capture vast agricultural fields and natural landscapes, and ML systems analyze these for crop health, pest spread, and environmental change patterns. This application supports precision farming because early detection enables targeted interventions rather than broad, expensive treatments.
Document and OCR analysis
Image processing powered by ML transforms scanned documents into structured digital text using pattern and character recognition. This machine learning image analysis supports automation in offices, banks, and archives because it handles handwriting and varied document layouts more reliably than rule-based OCR alone.
Challenges and Limitations of Machine Learning in Image Processing
 Machine learning works great in image processing, but it does not work “for free.” Every strong result comes from strong data, strong computing, and careful monitoring. So before you deploy machine learning in image processing, you need to understand what can go wrong.
Machine learning works great in image processing, but it does not work “for free.” Every strong result comes from strong data, strong computing, and careful monitoring. So before you deploy machine learning in image processing, you need to understand what can go wrong.
Data hunger
ML models need large, diverse datasets to learn real-world variation. Labeling images costs time and money because humans must draw boxes, masks, or tags. This becomes a major barrier in image processing using machine learning projects, especially in healthcare and manufacturing.
Label quality
Models learn whatever the dataset teaches them, including mistakes. If labels are inconsistent, the model learns wrong boundaries and wrong patterns. This hurts image classification using machine learning and becomes even worse for segmentation tasks.
Compute cost
Deep models need GPUs or TPUs to train at a useful speed. Training large vision models can take hours to days depending on dataset size and architecture. This is a real limitation for teams building deep learning in image processing systems on a tight budget.
Sensitivity to poor image quality
ML models struggle when images are too dark, blurry, or low resolution. A cracked surface might disappear under compression artifacts, or a tumor boundary might look too soft in noisy scans. That is why teams add noise reduction using machine learning and image enhancement using machine learning before making predictions.
Overfitting and underfitting
Overfitting happens when the model memorizes training images instead of learning general patterns. Underfitting happens when the model stays too simple and misses the signal. Both problems appear often in ML in image processing when datasets are small or poorly balanced.
How Webisoft Mitigates These Challenges
 Webisoft tackles machine learning challenges by combining deep engineering. Our expertise with disciplined AI development practices. Webisoft builds systems that don’t just predict well in the lab but perform reliably in real, changing environments. This helps enterprises deploy machine learning in image processing with confidence and measurable outcomes.
Webisoft tackles machine learning challenges by combining deep engineering. Our expertise with disciplined AI development practices. Webisoft builds systems that don’t just predict well in the lab but perform reliably in real, changing environments. This helps enterprises deploy machine learning in image processing with confidence and measurable outcomes.
Data Quality and Label Governance
Webisoft begins by auditing your raw data and labels to ensure image datasets cover real-world variation before training starts. Webisoft then applies professional data cleaning, normalization, and strategic augmentation to improve model learning. This data discipline strengthens machine learning for image processing accuracy and reduces costly retraining cycles.
Smarter Training With Transfer Learning
Webisoft accelerates model training by fine-tuning pre-trained vision models instead of building from scratch. This shortens development time and improves performance on small or specialized datasets such as medical scans or industrial parts. This method is especially effective for image classification using machine learning in domains where labeled data is scarce.
Robust Preprocessing for Noisy and Low-Quality Images
Webisoft strengthens model inputs with robust preprocessing pipelines that handle blur, poor lighting, and compression artifacts. By combining classic vision techniques with modern methods, Webisoft improves prediction stability on real feeds. This makes AI image processing solutions reliable even with low-quality or noisy source images.
Generalization Controls to Reduce Overfitting
Webisoft prevents overfitting by using regularization, cross-validation, and early stopping during training. Webisoft also tests models across varied subsets of data to ensure performance remains strong on unseen cases. This practice enhances the ability of ML in image processing systems to generalize beyond the training set.
Cost Optimization With Efficient Model Architectures
Webisoft chooses efficient model architectures that balance speed and accuracy to reduce computational cost. Webisoft applies techniques like model pruning, quantization, and distillation when appropriate to make deployment cheaper and faster. This approach keeps computer vision machine learning solutions scalable without overspending on hardware.
Edge and Cloud Deployment Strategy for Scale
Webisoft deploys ML models where they perform best: on edge devices for low latency and in the cloud for heavy workloads. This flexibility ensures automated image analysis using AI can operate reliably at global scale and meet performance targets. Webisoft’s multi-environment strategy also reduces operational bottlenecks at peak demand.
Explainability Layer for High-Stakes Decisions
Webisoft integrates explainability tools so stakeholders can understand model decisions and visualize what factors influenced outcomes. This transparency is critical when ML decisions affect compliance, safety, or customer trust. Webisoft’s explainable layers make machine learning image analysis easier to validate in regulated industries.
Bias Checks and Fairness Testing
Webisoft proactively tests training datasets to identify and correct potential biases before deployment. Webisoft applies fairness metrics and sampling strategies to ensure equitable performance across diverse data groups. This reduces the risk of bias in systems like image recognition using machine learning in security, hiring, and customer analytics.
Security Hardening Against Adversarial Inputs
Webisoft fortifies models by training with challenging or adversarial examples to harden them against subtle input changes. Webisoft also embeds preprocessing and validation checks to remove noise that could mislead vision systems. These defenses improve robustness in high-risk use cases like object detection using machine learning in autonomous or industrial systems.
Continuous Monitoring and Retraining for Drift Control
Webisoft monitors deployed models for performance drift as real data evolves over time. Webisoft designs retraining pipelines that adapt to new conditions and maintain accuracy throughout the model lifecycle. This ensures convolutional neural networks for image processing remain relevant and efficient long after deployment.
Turn real-world images into real business decisions with Webisoft.
Book a free consultation – Get a production-ready ML vision system built for accuracy, speed, and long-term stability.
Conclusion
Machine learning in image processing has changed how businesses handle visual data. Instead of relying on rigid rules that break under noise, lighting shifts, or real-world variability, ML models learn patterns directly from images and improve with better data.
This makes them more reliable for tasks like classification, detection, segmentation, and enhancement across industries such as healthcare, manufacturing, security, and retail. Still, success depends on the right dataset, strong preprocessing, proper training, and ongoing monitoring.
When done correctly, ML-based image processing delivers scalable accuracy, faster decisions, and long-term performance that traditional pipelines struggle to maintain.
FAQs
1. What is machine learning in image processing?
Machine learning in image processing means using trained models to analyze and understand images instead of relying only on fixed rules and filters. The model learns patterns from image data and then applies that learning to new images. This helps systems recognize objects, detect defects, and improve image quality.
2. How is machine learning different from traditional image processing?
Traditional image processing uses hand-written rules like edge detection, thresholding, and filtering. Machine learning learns features from data, so it adapts better to real-world variation like lighting changes, blur, and background clutter. That’s why ML performs better for complex tasks like detection and segmentation.
3. What are the most common uses of machine learning in image processing?
The most common uses include image classification, object detection, segmentation, facial recognition, defect inspection, and medical scan analysis. ML is also widely used for denoising, restoration, and super-resolution. These applications help automate visual decisions at scale.
