Share
Machine Learning Algorithms | Definition, Types, & Mechanics

- BLOG
- Artificial Intelligence
- January 2, 2026
Machine learning algorithms are the reason your phone predicts your next word, your bank flags suspicious transactions, and streaming platforms recommend movies. Behind every “smart” system sits an algorithm making calculated guesses from data. These algorithms do not think, feel, or improvise.
They follow math, patterns, and feedback, sometimes brilliantly and sometimes painfully wrong. Choosing the wrong algorithm can mean wasted time, biased results, or models that fail the moment reality changes.
Here you get a breakdown of ML algorithms, real examples, practical comparisons, and guidance for choosing the right approach without theory overload.
Contents
- 1 What Are Machine Learning Algorithms?
- 2 How Machine Learning Algorithm Learn From Data
- 3 The Main Types of Machine Learning Algorithms
- 4 Build production ready machine learning systems with Webisoft!
- 5 Supervised Machine Learning Algorithms
- 6 Unsupervised Machine Learning Algorithms
- 7 Reinforcement Learning Algorithms
- 8 Supervised vs Unsupervised vs Reinforcement Learning
- 9 How to Choose the Right Machine Learning Algorithm
- 9.1 Define the problem you are trying to solve
- 9.2 Understand the nature of your data
- 9.3 Evaluate data size and dimensionality
- 9.4 Consider model interpretability requirements
- 9.5 Assess computational and time constraints
- 9.6 Account for data quality and noise
- 9.7 Align the algorithm with deployment needs
- 10 How Webisoft Helps You Apply Machine Learning Algorithms in Production
- 11 Build production ready machine learning systems with Webisoft!
- 12 Conclusion
- 13 Frequently Asked Question
What Are Machine Learning Algorithms?
Machine learning algorithms are systematic computational methods designed to learn patterns, relationships, and rules directly from data.
Rather than relying on fixed instructions, they use mathematical and statistical techniques to analyze input data and determine how different variables relate to an outcome.
Each algorithm follows a specific learning approach, such as learning from labeled examples, identifying hidden structures in unlabeled data, or improving decisions through feedback and rewards.
These algorithms govern how machine learning development systems are trained, how errors are evaluated, parameters updated, and predictions generated for real-world applications.
How Machine Learning Algorithm Learn From Data
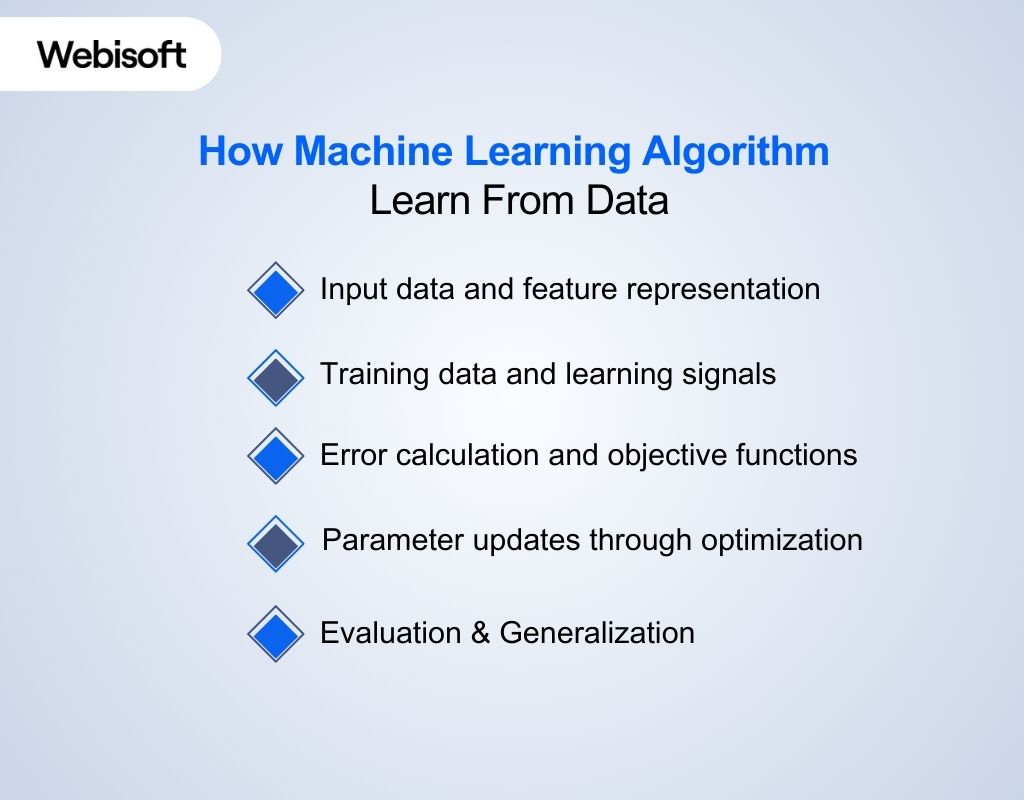 Machine learning algorithms follow a structured learning process that converts raw data into actionable patterns. Instead of memorizing inputs, they rely on mathematical feedback loops to improve predictions and decision logic over time. The learning process can be broken down into the following stages.
Machine learning algorithms follow a structured learning process that converts raw data into actionable patterns. Instead of memorizing inputs, they rely on mathematical feedback loops to improve predictions and decision logic over time. The learning process can be broken down into the following stages.
Input data and feature representation
Machine learning algorithm begin with raw data that is transformed into structured features. These features represent measurable attributes that the algorithm can interpret, such as numerical values, encoded categories, or extracted signals from text and images.
Training data and learning signals
Algorithms learn by observing training data that may include labels, target outputs, or feedback signals. This information defines what the algorithm is expected to predict, classify, or optimize during the learning process.
Error calculation and objective functions
Each algorithm evaluates its performance by comparing predicted results with expected outcomes. An objective function quantifies this difference, providing a clear measure of error or success that guides learning.
Parameter updates through optimization
Using the error signal, the algorithm adjusts internal parameters through optimization techniques. This iterative adjustment reduces error step by step and improves performance across repeated training cycles.
Evaluation & Generalization
After training, the model’s performance is tested on a separate, previously unseen dataset to ensure it captures underlying relationships rather than simply memorizing specific training examples. This process validates the model’s ability to generalize, ensuring reliable performance and accurate predictions when deployed in real-world scenarios.
The Main Types of Machine Learning Algorithms
 Machine learning algorithms are commonly grouped based on how they learn from data and the kind of feedback they receive during training. This classification forms a practical machine learning algorithms list used to compare approaches and outcomes.
Machine learning algorithms are commonly grouped based on how they learn from data and the kind of feedback they receive during training. This classification forms a practical machine learning algorithms list used to compare approaches and outcomes.
Supervised learning algorithms
These algorithms learn from labeled datasets where each input is paired with a known output. The learning process focuses on mapping inputs to correct outcomes, making this type suitable for predictive analytics use cases where historical examples are available.
Unsupervised learning algorithms
Unsupervised algorithms work with unlabeled data and focus on identifying patterns, relationships, or structures within the dataset. They are commonly used for grouping similar data points, reducing data complexity, or uncovering hidden trends.
Reinforcement learning algorithms
Reinforcement learning algorithms learn through interaction with an environment rather than fixed datasets. They improve decision-making by receiving feedback in the form of rewards or penalties, allowing them to optimize actions over time.


Build production ready machine learning systems with Webisoft!
Talk with our engineers to deploy reliable machine learning solutions.
Supervised Machine Learning Algorithms
 Among the main types of machine learning algorithms, supervised learning is the most widely applied in practice.
Among the main types of machine learning algorithms, supervised learning is the most widely applied in practice.
Here, you will see how these algorithms function, where they are used, and what distinguishes approaches through machine learning algorithms example below.
Linear Regression
Linear regression learns how numerical input variables influence a continuous output by fitting a straight-line relationship between them.
- It calculates coefficients that represent how much each feature contributes to the final prediction.
- The model minimizes prediction error by adjusting these coefficients iteratively.
- Because the relationship is explicit, results are easy to interpret and validate.
Example: A retail company uses linear regression to predict monthly revenue based on ad spend, store traffic, and seasonal trends.
Logistic Regression
Logistic regression is used when the output represents categories rather than numeric values.
- It converts input features into probability scores using a logistic function.
- Final predictions are made by applying probability thresholds.
- The model supports explainable decision-making in risk-based systems.
Example: A SaaS platform predicts whether a user will cancel their subscription based on login frequency, support tickets, and feature usage.
Decision Tree
Decision trees learn by splitting data into smaller groups based on feature conditions that reduce uncertainty.
- Each split represents a rule derived from the data.
- The model continues splitting until it reaches a clear decision path.
- The resulting structure mirrors human decision-making logic.
Example: An insurance provider evaluates claims by branching decisions on policy type, claim amount, accident history, and coverage limits.
Random Forest
Random forest improves decision trees by combining many trees trained on different subsets of data.
- Each tree learns slightly different rules.
- Predictions are averaged or voted on to reach a final result.
- This reduces overfitting caused by relying on a single tree.
Example: A bank detects fraudulent card transactions by aggregating risk signals from hundreds of decision paths built on transaction history.
Support Vector Machine (SVM)
Support Vector Machines It works by finding an optimal hyperplane that separates different classes of data points in a high-dimensional space with the largest possible margin.
- The algorithm focuses on the most informative data points near the boundary.
- Kernel functions allow it to separate data that is not linearly separable.
- It performs well when classes have clear margins.
Example: A manufacturing system classifies defective versus non-defective products based on sensor readings and computer vision models.
k-Nearest Neighbors (k-NN)
k-NN makes predictions by comparing new data points with similar labeled examples.
- It measures similarity using distance metrics.
- No explicit training phase occurs, as all learning is instance-based.
- Prediction quality depends heavily on data distribution.
Example: An e-commerce site recommends products by finding customers with similar browsing and purchase behavior.
Naive Bayes
Naive Bayes uses probability distributions to determine how likely a data point belongs to a class.
- It calculates conditional probabilities for each feature.
- Assumes features contribute independently to the outcome.
- This simplification enables fast training and scalability.
Example: A customer support system classifies incoming tickets by intent using word frequency patterns from past tickets.
Neural Networks
Neural networks learn layered representations of data through interconnected nodes.
- Early layers capture simple patterns, while deeper layers learn complex structures.
- Weights are adjusted iteratively to reduce prediction errors.
- Suitable for data where patterns are not easily expressed through rules.
Example: A media platform uses neural networks to recognize faces and objects in uploaded images
Gradient Boosting Algorithms
Gradient boosting trains models sequentially, with each new model focusing on correcting errors made earlier.
- The algorithm prioritizes difficult data points.
- Performance improves gradually with each iteration.
- Variants like XGBoost and LightGBM optimize speed and accuracy.
Example: A telecom company predicts customer churn by incrementally refining predictions based on usage patterns and service history
Unsupervised Machine Learning Algorithms
 Unsupervised machine learning algorithms work with unlabeled data and infer structure directly from input features. These algorithms rely on mathematical optimization, statistical inference, and similarity measurements to organize, transform, or model data without predefined outputs.
Unsupervised machine learning algorithms work with unlabeled data and infer structure directly from input features. These algorithms rely on mathematical optimization, statistical inference, and similarity measurements to organize, transform, or model data without predefined outputs.
K-Means Clustering Algorithm
An iterative algorithm that partitions data into a fixed number of clusters using distance-based optimization.
- The algorithm begins by initializing a predefined number of cluster centers, known as centroids.
- Each data point is assigned to the nearest centroid based on a distance metric such as Euclidean distance.
- Centroids are recalculated as the mean of all points assigned to each cluster.
- This assignment and update process repeats until centroid positions stabilize or convergence criteria are met.
Example: A numerical dataset of customer attributes is grouped based on proximity in feature space.
Hierarchical Clustering Algorithm
An algorithm that builds a hierarchical representation of data based on similarity relationships, nested structure of clusters, known as a dendrogram.
- The algorithm progressively merges individual data points into clusters or splits clusters into smaller groups.
- Similarity between clusters is computed using linkage methods such as single, complete, or average linkage.
- Cluster relationships are maintained across multiple levels, allowing analysis at different granularities.
- The final structure is represented as a dendrogram illustrating nested cluster relationships.
Example: A set of documents is organized into a hierarchy based on similarity scores.
DBSCAN Algorithm
A density-based clustering algorithm that identifies clusters using neighborhood density criteria.
- The algorithm defines clusters as regions where data points are densely packed together.
- Core points are identified based on a minimum number of neighbors within a specified radius.
- Clusters expand by connecting points that are density-reachable from core points.
- Data points in low-density regions are labeled as noise rather than being forced into clusters.
Example: Spatial coordinate data is analyzed to separate dense regions from isolated points.
Principal Component Analysis (PCA)
A linear transformation algorithm that reduces data dimensionality by maximizing variance.
- PCA computes a new set of orthogonal features called principal components.
- Each component captures the maximum possible variance remaining in the data.
- Components are ranked in order of importance based on their variance contribution.
- The transformation reduces redundancy while preserving the dominant structure of the dataset.
Example: High-dimensional sensor measurements are transformed into a smaller set of components.
t-Distributed Stochastic Neighbor Embedding (t-SNE)
A nonlinear algorithm designed to preserve local similarity relationships during dimensionality reduction.
- The algorithm converts distances between data points into probability-based similarity scores.
- Similarities are modeled in both high-dimensional and low-dimensional spaces.
- An optimization process minimizes divergence between these similarity distributions.
- The resulting representation emphasizes local neighborhood structure over global distances.
Example: Feature embeddings are visualized in two dimensions to inspect local groupings.
Apriori Algorithm
An iterative algorithm that discovers frequent item combinations using frequency thresholds.
- The algorithm generates candidate itemsets starting from individual items.
- It applies the downward closure property to eliminate infrequent candidates early.
- Each iteration expands only those itemsets that meet minimum support requirements.
- Multiple dataset scans are used to validate frequency at each level.
Example: Transaction records are processed to detect recurring combinations of items.
FP-Growth Algorithm
A tree-based algorithm that efficiently extracts frequent patterns without candidate generation.
- The algorithm compresses the dataset into a compact tree structure.
- Common item prefixes are shared within the tree to reduce redundancy.
- Frequent patterns are extracted through recursive traversal of the tree.
- This approach significantly reduces computational overhead for large datasets.
Example: Large-scale transaction data is analyzed using a compressed frequency tree.
Reinforcement Learning Algorithms
 Reinforcement learning algorithms are used when decisions are learned through interaction and feedback rather than predefined data.
Reinforcement learning algorithms are used when decisions are learned through interaction and feedback rather than predefined data.
This section explains how these algorithms improve actions over time by responding to rewards and penalties within an environment.
Q-Learning
Q-Learning is a value-based reinforcement learning algorithm that learns the quality of actions in given states.
- Maintains a Q-table that stores expected rewards for state–action pairs.
- Updates values based on future reward estimates.
- Does not require a model of the environment.
Example: Training a delivery robot to choose routes that minimize travel time by learning from past navigation outcomes.
SARSA
SARSA is similar to Q-Learning but updates values based on the action actually taken by the agent.
- Follows an on-policy learning approach.
- Learn more conservatively than Q-Learning.
- Useful when real-time decision stability matters.
Example: Teaching a robotic arm to adjust movements safely while operating near humans.
Deep Q-Networks (DQN)
Deep Q-Networks combine neural networks with Q-Learning to handle large or continuous state spaces.
- Uses neural networks instead of Q-tables.
- Learn directly from high-dimensional inputs such as images.
- Requires experience replay to stabilize learning.
Example: Training a game-playing system to learn optimal strategies from raw screen data.
Policy Gradient Methods
Policy gradient algorithms learn a policy directly rather than estimating action values.
- Optimizes actions by maximizing expected rewards.
- Handles continuous action spaces effectively.
- Suitable for complex control problems.
Example: Optimizing robotic locomotion by learning smooth movement policies.
Actor-Critic Algorithms
Actor-Critic methods combine value-based and policy-based learning.
- The actor selects actions based on a policy.
- The critic evaluates actions using value estimates.
- Balances learning stability and performance.
Example: Managing dynamic pricing strategies that adapt to customer behavior in real time
Supervised vs Unsupervised vs Reinforcement Learning
After reviewing how supervised, unsupervised, and reinforcement learning algorithms function individually, it is important to understand how these approaches differ in practice.
This comparison highlights how each learning type uses data, receives feedback, and fits specific problem settings.
| Aspect | Supervised Learning | Unsupervised Learning | Reinforcement Learning |
| Type of data used | Labeled data with known outcomes | Unlabeled data without predefined targets | Interaction data generated through actions |
| Learning feedback | Direct error comparison with actual results | No explicit feedback or correct answers | Rewards and penalties from the environment |
| Primary objective | Learn a mapping between inputs and outputs | Discover patterns or structure in data | Learn an optimal action strategy |
| Common tasks | Classification and regression | Clustering and dimensionality reduction | Sequential decision-making and control |
| Learning process | Adjusts predictions to minimize error | Groups or transforms data based on similarity | Improves actions based on cumulative rewards |
| Output type | Predicted class or numerical value | Clusters, components, or associations | Policy or action strategy |
| Data dependency | Requires high-quality labeled datasets | Works without manual labeling | Depends on environment interactions |
| Typical use scenarios | Spam detection, price prediction | Customer segmentation, anomaly detection | Robotics, game playing, adaptive systems |
| Model update behavior | Trained on historical datasets | Trained once or periodically on datasets | Continuously learns during interaction |
How to Choose the Right Machine Learning Algorithm
 Once you understand the different types of machine learning algorithms with examples, the next step is selecting the right one for your problem.
Once you understand the different types of machine learning algorithms with examples, the next step is selecting the right one for your problem.
This choice depends less on the algorithm’s popularity and more on your data, objectives, and operational constraints. The points below outline the practical factors that guide algorithm selection in real-world scenarios.
Define the problem you are trying to solve
Start by clearly identifying whether your task involves prediction, classification, pattern discovery, or decision-making. The problem type directly determines whether supervised, unsupervised, or reinforcement learning is appropriate.
Understand the nature of your data
Analyze whether your data is labeled, partially labeled, or completely unlabeled. The availability and quality of labels often narrow down algorithm choices more than any other factor.
Evaluate data size and dimensionality
Some algorithms perform well on small datasets, while others require large volumes of data to be effective. High-dimensional data may also require dimensionality reduction before applying certain algorithms.
Consider model interpretability requirements
If results need to be explained to stakeholders or regulators, simpler and more interpretable algorithms are often preferred. Complex models may offer higher accuracy but lower transparency.
Assess computational and time constraints
Training time, memory usage, and inference speed matter in production systems. Algorithms that perform well in theory may not be practical under limited computational resources.
Account for data quality and noise
Noisy, incomplete, or imbalanced data can affect algorithm performance. Some algorithms are more robust to noise, while others require careful preprocessing and feature engineering.
Align the algorithm with deployment needs
Consider how often the model needs retraining, how it will handle new data, and whether it must adapt in real time. These factors influence whether static or adaptive algorithms are suitable.
If you are evaluating a machine learning algorithm for a real product, expert guidance can prevent costly architectural and deployment mistakes. Talk with Webisoft to discuss your data, use cases, and production goals before implementation starts.
How Webisoft Helps You Apply Machine Learning Algorithms in Production
 Choosing the right machine learning algorithm is only the first step; building a reliable, scalable production system is where teams struggle.
Choosing the right machine learning algorithm is only the first step; building a reliable, scalable production system is where teams struggle.
Webisoft brings production experience and engineering depth to deliver dependable systems that integrate smoothly and create business value.
Strategic AI Opportunity Analysis
Before building a single model, Webisoft identifies where machine learning can create value in your business.
- Assess your data maturity and readiness.
- Maps high-impact use cases that align with business outcomes.
- Defines KPIs that matter for your organization
This strategic foundation ensures every machine learning effort drives real value, not just technical outputs.
Custom Model Architecture and Design
Webisoft designs customized machine learning architectures based on your specific data, workflows, and goals.
- Architects data pipelines, feature engineering, and model logic.
- Ensures models are explainable, compliant, and aligned with governance standards.
- Designs for performance and long-term adaptability.
This structured design phase supports scalability and enterprise readiness.
End-to-End Model Training and Development
Building models that work well in theory is different from building them to last in production. Webisoft engineers train and validate models with precision.
- Uses best-in-class frameworks like TensorFlow, PyTorch, and Scikit-learn.
- Tests against real business scenarios and edge cases.
- Optimizes models for reliability, accuracy, and stability.
This ensures models not only learn patterns but also perform consistently after deployment.
Seamless Integration with Existing Systems
Deploying machine learning in isolation limits its impact. Webisoft embeds ML systems directly into your workflows and tools.
- Connects models to ERP, CRM, analytics, and operational systems.
- Maintains data consistency across platforms.
- Enables ML-augmented decisions within existing processes
This integration approach prevents disruption and maximizes adoption across teams.
Enterprise-Grade Infrastructure & MLOps
Reliable production ML requires robust infrastructure and continuous maintenance, Webisoft builds both.
- Implements secure, scalable pipelines for data ingestion and model execution.
- Automates retraining, performance monitoring, and drift detection.
- Ensures compliance with global standards such as GDPR, HIPAA, and SOC 2.
This MLOps-enabled approach keeps your models accurate and performant as data evolves.
Continuous Monitoring, Optimization, and Support
Machine learning is dynamic, models degrade if left unattended. Webisoft supports ML systems long after deployment.
- Tracks performance metrics and business impact in real time.
- Updates models with fresh data and feedback loops.
- Provides ongoing optimization and support.
This continuous lifecycle approach ensures lasting ROI from your ML investments.
Build production ready machine learning systems with Webisoft!
Talk with our engineers to deploy reliable machine learning solutions.
Conclusion
Machine learning algorithms are not checklists to memorize or models to copy blindly. They are decision engines whose behavior changes with data, context, and constraints. When understood properly, they help teams predict smarter, detect risks earlier, and avoid systems that collapse outside controlled experiments.
Applying ML algorithms at scale is where most efforts succeed or fail. Webisoft helps organizations move past trial-and-error by engineering production-ready machine learning systems that integrate cleanly, perform reliably, and support long-term business goals.
Frequently Asked Question
How much data is needed to train a machine learning algorithm?
Data requirements depend on algorithm type, problem complexity, feature quality, and noise levels. Linear models may train with thousands of rows, while deep learning often needs millions, plus validation data, to generalize reliably and avoid overfitting.
Can a machine learning algorithm work with incomplete data?
Yes, Machine learning algorithm can operate with incomplete data, but performance suffers without proper handling.
Common approaches include imputation, feature removal, indicators for missingness, or algorithms that natively tolerate gaps, ensuring training reflects real-world data conditions.
Can one machine learning algorithm solve all problems?
No single machine learning algorithm fits every problem. Effectiveness varies with data size, structure, labels, constraints, and goals.
So practitioners compare multiple approaches, establish baselines, and select models that balance accuracy, interpretability, and operational requirements.
