Share
How to Train an AI Agent: Everything You Need to Know

- BLOG
- Artificial Intelligence
- October 18, 2025
You want to build something that learns and improves over time. But when you search for how to train an AI agent, you’re met with confusing terms: reinforcement learning, reward signals, neural networks. It’s easy to feel lost.
Where does the agent start? What does it need to understand? How do you teach it to make good choices and avoid mistakes?
Well, training an AI agent requires a solid grasp of basics, careful planning, the right tools, and learning from failures.
We’ll guide you step by step, so you understand how to train an AI agent and build one that improves and makes smart choices.
Contents
- 1 Background and Context
- 2 Core Concepts & Technical Foundations
- 3 Step-by-Step Implementation: How to Train an AI Agent
- 3.1 Step 1: Define the Environment and Task
- 3.2 Step 2: Choose a Reward Structure
- 3.3 Step 3: Represent States and Actions in Code
- 3.4 Step 4: Select a Learning Algorithm
- 3.5 Step 5: Initialize the Agent’s Policy or Value Function
- 3.6 Step 6: Start the Training Loop (Interaction & Learning)
- 3.7 Step 7: Implement Exploration Strategy
- 3.8 Step 8: Monitor Performance and Adjust Parameters
- 3.9 Step 9: Save and Test the Trained Agent
- 3.10 Step 10: Improve and Iterate
- 3.11 Summary Flowchart
- 3.12 Troubleshooting Tips
- 4 Plan Your AI Strategy with Webisoft now!
- 5 Challenges in Training an AI Agent
- 6 Advanced Use Cases & Real-World Scenarios
- 7 Tools, Libraries, and Frameworks for Training AI Agents
- 8 Common Mistakes & How to Avoid Them
- 9 Best Practices & Optimization Techniques
- 10 How Webisoft Can support You Train and Build AI Agents
- 11 Plan Your AI Strategy with Webisoft now!
- 12 Performance Considerations and Security Implications
- 13 Conclusion
- 14 FAQ
Background and Context
AI has grown quickly and moved from simple rule-based programs to smart AI agents. These AI agents watch what is happening, take actions, and learn to improve over time.
In the beginning, AI used fixed rules, but these rules were not very flexible. After that, machine learning appeared, especially reinforcement learning (RL). RL lets agents learn by trying things and getting rewards or penalties, just like people do. Because of this, AI agents can deal with new and shifting situations better.
However, training AI agents is still difficult. Rewards can be rare or arrive late, and learning needs time and strong computers. Also, agents trained in one place often do not work well somewhere else.
There are three main ways to train AI agents:
- Supervised learning means learning from examples with correct answers.
- Unsupervised learning means finding patterns without any answers.
- Reinforcement learning means learning by trying, receiving rewards or penalties, and improving.
Among these methods, RL works best for training AI agents because it fits well when decisions must be made in unknown situations. To do this, RL uses a math model called Markov Decision Process (MDP) to understand the environment, actions, and rewards.
With this simple background, it will be easier to follow the main steps of how to train an AI agent.
Core Concepts & Technical Foundations
Before jumping into how to train an AI agent, it’s important to understand the key concepts that form the foundation of how agents learn and make decisions. These concepts come from Reinforcement Learning (RL), the primary method for efficiently training an AI agent.
Key Terminology
| Term | Meaning (Simple) |
| Environment | The world or setting where the agent acts. |
| State | A snapshot of the environment at a moment (what agent senses). |
| Action | A choice or move the agent can make in the environment. |
| Reward | Feedback signal: positive or negative value for an action. |
| Policy | The agent’s strategy — a rule telling it what action to take in each state. |
| Value Function | An estimate of future rewards from a given state or action. |
Markov Decision Process (MDP) — The Formal Framework
At the core of training AI agents is the Markov Decision Process (MDP): a mathematical way to describe the environment and the agent’s interaction with it.
An MDP is made up of:
- States (S): All possible situations the agent can be in
- Actions (A): All possible moves the agent can make
- Transition function (T): Probability of moving from one state to another after an action
- Reward function (R): The immediate reward received after taking an action in a state
- Discount factor (γ): A number between 0 and 1 that controls how much future rewards count compared to immediate rewards
In simple terms: at each step, the agent sees the current state, picks an action, the environment changes state, and the agent gets a reward. The goal is to find the policy that maximizes the total rewards over time.
Exploration vs. Exploitation Dilemma
One important challenge is how the agent balances:
- Exploration: Trying new actions to discover better rewards
- Exploitation: Using known actions that give good rewards
Too much exploration wastes time; too much exploitation may cause the agent to miss better solutions. Effective training strategies balance both.
Overview of Core Reinforcement Learning Algorithms
There are several types of RL algorithms, but they mainly fall into two categories:
1. Value-based Methods
These approaches learn a value function either a state-value V(s)V or an action-value Q(s,a)- that predicts expected future reward.
Q-learning: learns an action-value function Q(s,a) estimating the return of taking action a in state s.
Deep Q-Network (DQN): replaces the Q-table with a neural network that approximates Q(s,a)allowing Q-learning to handle large or continuous state spaces while still assuming a discrete action set.
2. Policy-based Methods
These methods directly learn the policy, which maps states to actions without needing a value function.
- REINFORCE algorithm: Uses sampled returns to update policy parameters
- Proximal Policy Optimization (PPO): A more advanced algorithm balancing exploration and stable policy updates
3. Actor-Critic Methods
Combine value-based and policy-based ideas. The actor learns the policy, and the critic evaluates the policy by estimating the value function. Examples: A2C, A3C, PPO.
Diagram: Agent-Environment Interaction Loop (Simplified)

At every step:
- The agent observes the environment’s current state
- It selects an action to perform
- The environment returns the next state and a reward signal
- The agent updates its knowledge and repeats
This foundational understanding prepares us to implement training in practice.
Step-by-Step Implementation: How to Train an AI Agent

Training an AI agent may seem complicated at first, but when broken down into clear steps, it becomes manageable. Here is a beginner-friendly guide that explains how to train an AI agent from start to finish, connecting each step carefully.
Step 1: Define the Environment and Task
What to do: First, decide where your AI agent will act and what it needs to achieve.
- Define the environment the agent will interact with
- Specify the goal or task, e.g., playing a game, navigating a maze, or controlling a robot arm
- Identify possible states and actions the agent can take
Webisoft’s AI Strategy Consultation shows you how to plan your AI agent’s goal and where it will work. This way, you start with a clear plan that matches your needs.
Why it matters: The environment is the world your agent lives in. You need a clear setup so the agent knows what it sees (states), what it can do (actions), and what counts as success (rewards).
Example: For a simple grid world game, the environment is a grid, states are the agent’s positions on the grid, and actions could be moving up, down, left, or right.
Step 2: Choose a Reward Structure
What to do: Define how the agent gets feedback:
- Create a reward function that assigns positive rewards for good actions and negative rewards (penalties) for bad actions.
- Make sure the rewards encourage the behavior you want the agent to learn.
Why it matters: The reward function is the agent’s only guide for learning. It shapes the agent’s behavior by telling it what’s good or bad.
Example: In the grid game, give +10 points for reaching the goal, -1 for each move (to encourage faster completion), and -5 for hitting obstacles.
Step 3: Represent States and Actions in Code
What to do: Translate your environment, states, and actions into data structures your program can use.
- Represent states as arrays, numbers, or images depending on the task.
- Define actions as discrete choices or continuous values.
- Make sure your program can feed these into the learning algorithm.
Why it matters: The agent’s algorithm needs a clear, machine-readable format for states and actions to process and learn efficiently.
Example: States can be a tuple (x, y) for grid positions, and actions can be integers 0 = up, 1 = down, 2 = left, 3 = right.
Step 4: Select a Learning Algorithm
What to do: Pick a suitable reinforcement learning algorithm based on your problem complexity.
- For simple, small state-action spaces, try Q-learning.
- For larger or continuous spaces, use Deep Q-Networks (DQN) or Policy Gradient methods.
- Use libraries like Stable Baselines3, RLlib, or OpenAI Baselines to simplify implementation.
Why it matters: The algorithm defines how your agent learns from interactions and updates its strategy (policy).
Example: Use Q-learning if your environment is simple, like the grid world. Use DQN if your environment involves images or complex states, like Atari games.
Step 5: Initialize the Agent’s Policy or Value Function
What to do: Set up your agent’s initial knowledge.
- For value-based methods like Q-learning, initialize the Q-table with zeros or small random values.
- For neural network methods like DQN, initialize the network weights randomly.
Why it matters: Starting with neutral or random knowledge lets the agent learn from scratch based on experience.
Example (Q-learning): Create a table with rows = states, columns = actions, all values zero.
Step 6: Start the Training Loop (Interaction & Learning)
What to do: This is the heart of how to train an AI agent, where it learns from experience:
- Observe current state (s).
- Choose an action (a): Use the current policy (or epsilon-greedy exploration).
- Take action (a): Execute it in the environment.
- Observe reward (r) and next state (s’).
- Update the agent’s knowledge: Adjust policy or value function based on (s, a, r, s’).
- Repeat until stopping criteria (number of episodes, time limit, or performance threshold) is met.
Why it matters: The agent improves by repeatedly interacting with the environment and learning from rewards and new states.
Example (Q-learning update rule):
- alpha: learning rate (how much new info overrides old)
- gamma: discount factor (importance of future rewards)
Step 7: Implement Exploration Strategy
What to do: Use a method like epsilon-greedy to balance exploration and 
- With probability epsilon (e.g., 0.1), pick a random action to explore.
- Otherwise, pick the best-known action according to current policy.
Why it matters: Supports the agent discover better strategies instead of getting stuck in local optima.
Example:

Step 8: Monitor Performance and Adjust Parameters
What to do: Track metrics like cumulative rewards, episode length, or success rate.
- Visualize progress (e.g., reward over episodes)
- Tune hyperparameters like learning rate, discount factor, and epsilon.
- If the agent isn’t improving, try adjusting the reward function or network architecture.
Why it matters: Monitoring is a crucial part of how to train an AI agent, as it assists diagnosing problems and improves training efficiency.
Step 9: Save and Test the Trained Agent
What to do: After training, save the learned policy or model.
- Test the agent in the environment without exploration to see how well it performs.
- Evaluate on new or slightly different environments to check generalization.
Why it matters: Testing confirms whether your agent has learned to perform the task reliably, an essential step in how to build an AI agent that works outside of training conditions.
Step 10: Improve and Iterate
What to do: AI agent training is rarely perfect on the first try.
- Try different reward functions.
- Use more advanced algorithms (like PPO, A3C).
- Add techniques like experience replay or target networks.
- Experiment with network architectures or feature representations.
Why it matters: Iteration leads to better performance and robustness.
Summary Flowchart
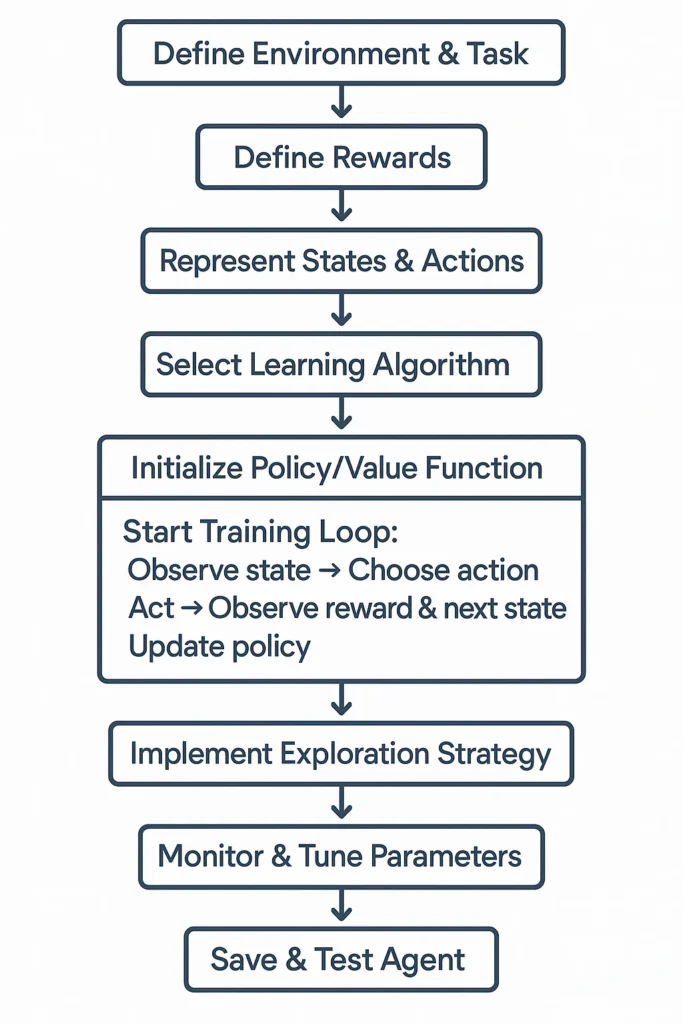
Troubleshooting Tips
- If training seems slow, try fewer timesteps or a simpler environment.
- If the agent’s performance is poor, increase training time or tune hyperparameters.
- Make sure to install the latest versions of Gym and Stable Baselines3.


Plan Your AI Strategy with Webisoft now!
Schedule a Call and reach out now for expert help.
Challenges in Training an AI Agent
Well, training AI agents can be hard because of these reasons:
- Rewards can be rare or come late, so learning is slow
- Agents must balance trying new things and using what works best
- Training needs a lot of computer power and time
- Agents trained in one place might not work well somewhere else
Because of all these issues, researchers are working hard to find smarter, faster, and more flexible ways to train AI agents that can adapt to many kinds of real-world tasks.
Advanced Use Cases & Real-World Scenarios

Once you understand the steps of how to train an AI agent in a simple environment, there are many advanced challenges and exciting real-world applications. Let’s explore some key advanced topics that push the boundaries of AI agent training.
Let’s begin with a quick overview of the advanced topics:
| Advanced Use Case | Description | Example |
| Multi-Agent Systems | Training multiple interacting agents | AI teams in multiplayer games |
| Curriculum & Transfer Learning | Learning from simple to complex; reusing skills | Robots learning basic walking before running |
| Continuous Action Spaces | Handling infinite action possibilities | Drone speed and angle control |
| Partially Observable Environments | Learning under uncertainty and incomplete info | Self-driving cars with limited sensor view |
| Real-World Applications | Robotics, gaming, finance, healthcare | AlphaGo, robotic arms, trading bots |
Multi-Agent Systems Training
What it means: Instead of training just one agent, you train multiple agents that interact with each other and the environment.
- Agents can cooperate (work together) or compete (like players in a game).
- Examples: multiple robots working in a warehouse, or AI players in multiplayer video games.
Why it’s challenging:
- The environment becomes more complex because each agent’s action affects others.
- Agents must learn not only about the environment but also about other agents’ behaviors.
- Training requires techniques like self-play where agents learn by playing against themselves or others.
Example: OpenAI’s famous Dota 2 AI trained multiple agents playing against each other, improving through competition.
Curriculum Learning and Transfer Learning
Curriculum Learning: Training the agent on simpler tasks first, then gradually increasing the difficulty.
- supports the agent learning complex behaviors step by step.
- Similar to how humans learn (start easy, then harder).
Transfer Learning: Using knowledge learned in one task/environment to speed up learning in another related task.
- Instead of training from scratch, reuse learned skills or models.
- Saves time and resources.
Example: Train a robot to walk on flat ground, then transfer that knowledge to walk on uneven terrain.
Handling Continuous Action Spaces
What it means: Many real-world tasks don’t have just a few discrete actions (like move left/right), but a continuous range of possible actions (like how fast to move or the exact angle of a robotic arm).
Challenges:
- Discrete action methods like Q-learning don’t work directly.
- Need algorithms designed for continuous control like Deep Deterministic Policy Gradient (DDPG) or Proximal Policy Optimization (PPO).
Example: Controlling a drone’s exact speed and direction in 3D space requires continuous action control.
Training Agents in Partially Observable Environments (POMDPs)
What it means: In many real scenarios, the agent cannot fully observe the environment state. It gets incomplete or noisy observations.
- These are called Partially Observable Markov Decision Processes (POMDPs).
- Agents need to remember past observations or use models to infer hidden information.
Techniques:
- Use Recurrent Neural Networks (RNNs) or Long Short-Term Memory (LSTM) networks to give agents memory.
- Implement belief states or probabilistic reasoning to handle uncertainty.
Example: A self-driving car may not always have full information about other vehicles hidden behind obstacles.
Real-World Applications
Learning how to create an AI agent or how to train an AI agent that works in real environments is becoming more practical. These agents are now used in many fields through reinforcement learning and similar methods.
- Robotics: Robots learning to grasp objects, walk, or navigate complex terrains.
- Games: AI agents mastering video games, board games (e.g., AlphaGo beating human champions).
- Finance: Automated trading agents that learn to buy/sell stocks or manage portfolios.
- Healthcare: Agents managing treatment plans or optimizing hospital resources.
- Recommendation Systems: Agents that learn to personalize content or ads over time.
Tools, Libraries, and Frameworks for Training AI Agents
Training AI agents from scratch can be challenging, but luckily, there are many powerful tools and libraries that simplify this process. These tools provide ready-to-use environments, algorithms, and utilities so you can focus on learning and experimentation.
OpenAI Gym
What it is: A widely-used toolkit that provides many pre-built environments for reinforcement learning.
- Includes simple games, control tasks, and simulated robotics.
- Offers a standard interface to interact with different environments.
- Great for beginners to test algorithms on various problems.
Why use it: You don’t need to create environments from zero. OpenAI Gym simplifies how to train an AI agent by letting you focus on model behavior and reward structures.
Example: You can easily load the classic CartPole balancing task:

Stable Baselines3
What it is: A set of high-quality implementations of popular RL algorithms built on PyTorch.
- Helps algorithms like DQN, PPO, A2C, SAC, and more.
- Easy to train and evaluate agents with a few lines of code.
- Well-documented and maintained.
Why use it: Speeds up experimentation by providing reliable, ready-made RL algorithms.
Example: Training a PPO agent on CartPole:

RLlib (Ray)
What it is: A scalable RL library designed for distributed training.
- Helps large-scale training on clusters or clouds.
- Great for advanced users and multi-agent setups.
- Integrates with many ML frameworks.
Why use it: If your project grows large or needs multi-agent training, RLlib scales easily.
TensorFlow Agents (TF-Agents)
What it is: A library from Google that provides modular components to build RL algorithms using TensorFlow.
- Good for users comfortable with TensorFlow.
- Assists custom environments and complex algorithms.
Unity ML-Agents
What it is: A toolkit that integrates AI training with the Unity game engine.
- Allows training agents in 3D simulated environments.
- Useful for robotics, games, and realistic simulations.
Additional useful Tools
- OpenAI Baselines: Original implementations of RL algorithms.
- Keras-RL: Easy RL library built on Keras.
- PettingZoo: Multi-agent RL environments.
- Garage: A toolkit for developing and evaluating RL algorithms.
How to Choose the Right Tool?
| Tool | Beginner Friendly | Algorithms Included | Environment Support | Scalability |
| OpenAI Gym | Yes | No (environments only) | Many classic tasks | Basic |
| Stable Baselines3 | Yes | Many (DQN, PPO, A2C, etc.) | Any Gym environment | Moderate |
| RLlib | Moderate | Many | Gym + Custom + Multi-agent | High (distributed) |
| TF-Agents | Moderate | Many | Custom TensorFlow env | Moderate |
| Unity ML-Agents | Moderate | PPO, SAC, etc. | 3D simulations (Unity) | Moderate to High |
Summary: Recommended Starting Setup for Beginners
- Start with OpenAI Gym to practice and test environments.
- Use Stable Baselines3 to apply popular algorithms quickly.
- Move to RLlib or Unity ML-Agents when ready for complex or multi-agent training.
Common Mistakes & How to Avoid Them
Training AI agents can be tricky, especially when you’re starting out. Many beginners run into similar problems that slow progress or cause confusing results. Let’s cover some common mistakes and how to fix them.
| Common Mistake | What Happens | Why It’s Bad | How to Avoid It |
| 1. Undefined Problem | Starting training without a clear goal or success metric | Hard to measure progress or success | Define the task, environment, actions, and rewards clearly |
| 2. Poor Reward Design | Rewards don’t guide learning properly | Agent learns wrong behavior or gets stuck | Design frequent, meaningful rewards; use intermediate rewards |
| 3. Ignoring Exploration | Agent repeats known actions, never tries new ones | Misses better strategies or solutions | Use exploration techniques like epsilon-greedy or noise |
| 4. Training Too Little/Long | Training for too few or too many timesteps | Undertraining or wasted time; possible overfitting | Monitor rewards, use early stopping, validate performance |
| 5. Wrong Algorithm Choice | Using algorithms not suited to the problem/environment | Poor learning or inefficiency | Match algorithm to problem type (discrete vs continuous) |
| 6. No Input Preprocessing | Feeding raw, unprocessed data to the agent | Difficult for agent to learn meaningful patterns | Normalize inputs, use relevant features |
| 7. Overfitting / Poor Generalization | Agent performs well only on training environments | Fails in new or real-world situations | Train on varied data, regularize, test on unseen data |
| 8. No Hyperparameter Tuning | Using default or random hyperparameters without tuning | Degraded learning speed and quality | Systematically tune learning rates, batch sizes, etc. |
Best Practices & Optimization Techniques
Training an AI agent is a journey where careful planning and efficient adjustments lead to success. Follow these best practices to make your training efficient, effective, and stable.
| Best Practice | Description | Why It Helps |
| Start Simple | Begin with easy tasks and small models | Easier debugging and faster iteration |
| Reward Shaping | Give frequent, guiding rewards | supports agent learn desired behavior faster |
| Normalize Inputs/Rewards | Scale data to consistent ranges | Stabilizes and speeds up training |
| Choose Right Algorithm | Match algorithm to action type | Make sure efficient and effective learning |
| Use Replay Buffers | Reuse past experiences | Stabilizes training and improves sample efficiency |
| Implement Exploration | Add randomness or entropy | Avoids getting stuck in suboptimal policies |
| Monitor Metrics | Track training progress visually | Early problem detection |
| Save & Validate Models | Regular checkpoints and tests | Prevents data loss and confirms generalization |
| Tune Hyperparameters | Systematic adjustment of key parameters | Optimizes training speed and final performance |
| Transfer & Curriculum Learning | Use simpler tasks or pretrained models first | Accelerates learning on complex tasks |
How Webisoft Can support You Train and Build AI Agents
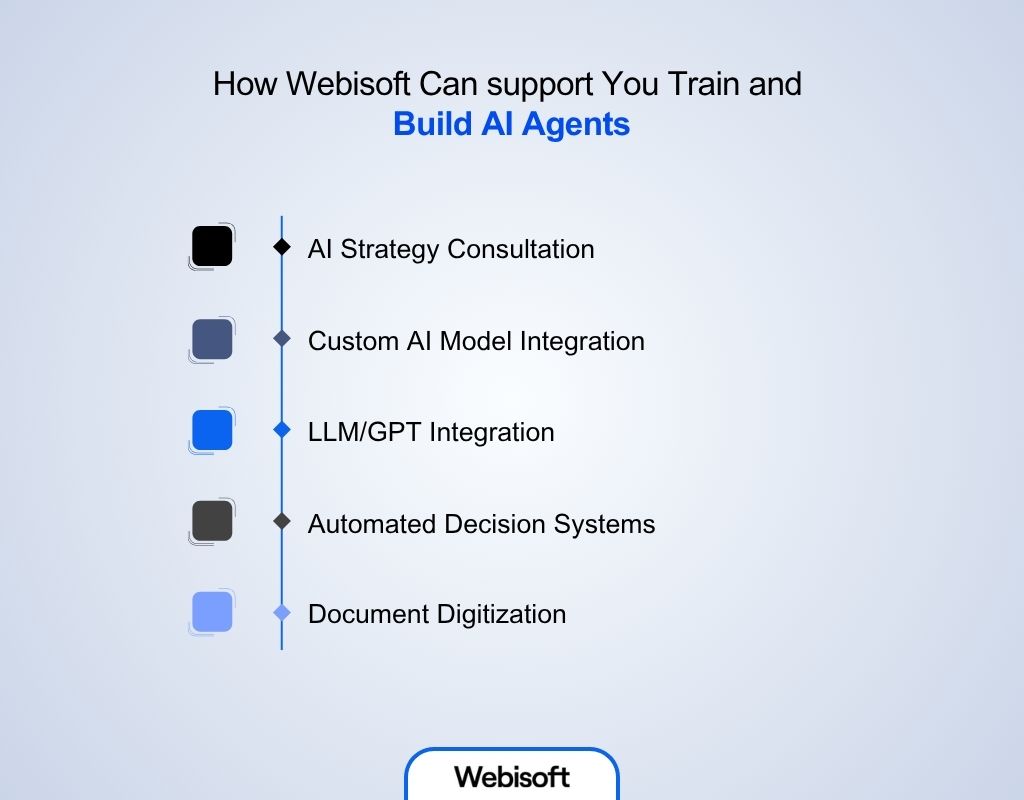
Training an AI agent is like teaching a smart student, it needs the right data, tools, and help to learn well. Webisoft gives you everything you need to train your AI agent step by step, and also assists you build it for real-world use.
Here’s how Webisoft can help:
- AI Strategy Consultation: First, they support you to decide what your AI agent should learn and why—this sets a clear goal for training.
- Custom AI Model Integration: They guide you in choosing or building AI models that can be trained to do your specific tasks.
- LLM/GPT Integration: Webisoft uses advanced language tools like GPT to train your agent in understanding and replying with natural language.
- Automated Decision Systems: They assist your AI learn how to make quick decisions by working with large sets of real-time data.
- Document Digitization (OCR): Webisoft can turn paper or scanned documents into clean digital data—so your AI can use it for learning.
With Webisoft, your AI agent gets a strong foundation, clear training goals, and the right tools to grow smarter over time.
Plan Your AI Strategy with Webisoft now!
Schedule a Call and reach out now for expert help.
Performance Considerations and Security Implications
When learning how to train an AI agent, it’s important to think about how well the agent performs and to keep the training process secure.
Performance Considerations
Computational Resources: Training AI agents, especially those using deep learning, often requires powerful hardware like GPUs. These specialized processors speed up the calculations needed during training. If your local computer is not powerful enough, cloud computing services such as AWS or Google Cloud provide scalable options to handle heavy workloads.
Training Time: The time it takes to train an AI agent can vary widely—from hours to even weeks—depending on the complexity of the task and the size of the model. Monitoring your agent’s learning progress is essential to avoid wasting time on training runs where the agent is no longer improving. Techniques like early stopping support save resources by halting training once performance plateaus.
Sample Efficiency: Some training algorithms are better at learning from fewer interactions with the environment. These off-policy algorithms, such as DQN or SAC, reuse past experiences efficiently, reducing the amount of new data needed. In contrast, on-policy methods like PPO often require more interactions but tend to be easier to implement.
Scalability: Complex environments or multi-agent systems may require training that runs across multiple computers simultaneously. Distributed training frameworks like RLlib enable this by coordinating the training process on many machines, speeding up learning and allowing more complex scenarios to be handled.
Security Implications
Data Integrity: The quality and trustworthiness of the data or simulated environment used during training are critical. If this data is tampered with or poisoned, it can cause the agent to learn incorrect or harmful behaviors. Always make sure your training data is secure and validated.
Model Robustness: Once trained, an AI agent should be tested against unexpected or adversarial inputs. This testing confirms that the agent behaves safely and reliably even when faced with situations it didn’t see during training, which is especially important for real-world applications.
Privacy Concerns: If your training involves sensitive information, protecting that data is crucial. Using encryption and secure storage methods prevents unauthorized access. Additionally, anonymizing data where possible minimizes privacy risks.
Ethical Considerations: Finally, always consider the ethical implications of your agent’s behavior. Avoid training models that might reinforce biases or cause harm. Regular reviews and testing can support making sure the agent behaves in a fair and responsible way.
Conclusion
Learning how to train an AI agent may seem complex at first, but by understanding the key steps and best practices, you can build effective and reliable agents.
Importantly, be mindful of the resources you use and the security of your training data and models. Make sure your agent can handle unexpected situations and behaves ethically, especially if deployed in the real world. In addition, training AI agents takes many steps, but with good guidance and tools, anyone can succeed. For expert support, Webisoft provides AI development and consulting to build AI agents made just for you.
FAQ
Is labeled data always required to train an AI agent?
No, labeled data is not always needed. Some AI agents learn from labeled data, which means they have examples with correct answers to learn from. This is called supervised learning. But other AI agents learn without labeled data, by exploring and finding patterns on their own, which is called unsupervised learning or reinforcement learning. So, labeled data is helpful but not always required.
What role does simulation play in training AI agents?
Simulation is very useful for training AI agents because it lets them practice in a safe, virtual world. In a simulation, the AI can try many actions and learn from mistakes without real-world risks or costs. This helps the AI improve faster and test different situations before working in the real world.
How often should an AI agent be retrained or updated?
How often an AI agent needs retraining depends on how fast the world or the task changes. If new data or situations come up often, the AI should be updated regularly to stay accurate and useful. Some AI agents learn continuously, while others are retrained every few weeks or months. Keeping the AI updated helps it perform well over time.
