Share
Unlocking the Power of Caching: Accelerate Your Web3 Products

- BLOG
- Web3
- October 20, 2025
If you’re aiming to enhance the performance of your web3 products, understanding and effectively implementing caching strategies is vital. It plays a pivotal role in enhancing data retrieval speeds and operational efficiency. ensuring your web3 applications deliver top-tier performance.
It can be found on high-speed hardware, for instance, RAM, or inside the memory. By storing web3 data this way, we are able to retrieve data faster because we don’t have to dig through slower storage layers.
It’s like trading a little capacity for a big gain in speed when we’re dealing with a blockchain network. So, we’ll help you understand how caching can help you optimize web3 products and how it works.
Contents
What is the Significance of Caching in Web Applications?
Before we jump into more technical details of caching, let’s first understand its importance.

Data Retrieval Speed
Web apps are often bombarded with data requests, so how do they cope? A memory-based engines and RAM, my friend! They champion those output/input processes per second, far outpacing conventional data systems and disk-based systems.
Yes, you could throw more resources at those, but that could make your wallet cringe and still might not hit the same performance high as a memory-based cache. Bottom line, caching gets you top-notch data retrieval speed and helps you pinch pennies at scale.
High Performance
Caching isn’t a one-trick pony. It struts its stuff across numerous tech layers, from operating systems to networking layers like DNS and CDNs, databases, and web apps. Need to beef up IOPS and slice off latency in social networking, gaming, media sharing, or Q&A portals? Caches are the go-to.
And what can be cached? Let’s see – database query results, API communication, complex algorithms, and web content (you know, like Javascript, HTML, or even image files).
High-performance computing models and recommenders rely on memory-based data layers. Why? They need instant access to massive data sets stored on lots of machines, and the slow-footed nature of the supporting hardware can throw a wrench in the works when data is stored traditionally.
Enhance Dynamic Scalability
Caching plays nicely in a distributed computer setting. Think of it like a dedicated middleman, an independent layer that systems and applications can access without interfering with its own operations.
This is a big deal in systems with dynamic scalability. Why? Scaling can upset the Apple cart when caches are tied to the same system or node as their using applications. Local caches are kind of a loner, only useful to the application gobbling up the data.
But in a shared caching setup, it’s a whole new ball game. Data is spread among multiple servers, stored centrally, and available to all users. That’s caching for you, the unsung hero behind fast and efficient web applications.
Consider this: a group of digital architects devoted to creating online experiences that not just appear great but also operate very well. That’s the Webisoft crew! We don’t simply create websites; we create digital ecosystems that are optimized for the ever-changing internet terrain.
Best Standards of Caching
Putting a layer of caching in place? You’ve got to make sure the data’s legit. A thumbs-up sign? High hit rates. They tell you your cache is doing its job and the file is ready for pickup. No data in the cache? That’s a miss cache.
But don’t sweat it, tools like time to live (TTLs) can help us wave goodbye to expired data. Then, there’s the question of whether your cache environment needs to be always on deck. For that, memory-based tools like Redis are your go-to.
Need to stash data separately from cache it from the main source? A memory-based layer has got you covered. To figure out if that works for you, you need to set a Recovery Time Objective (RTO) and Recovery Point Objective (RPO) for your memory-based engine.
Different design approaches can be adopted for varied memory-based engines to satisfy most RPO and RTO demands.
What is the Purpose of Web3 Caching?
The thing with blockchains? Not so great at quick-fire data pulling. Users typically communicate with the blockchain system using RPC calls generated by the library of web3, which isn’t exactly Gonzales-speedy.
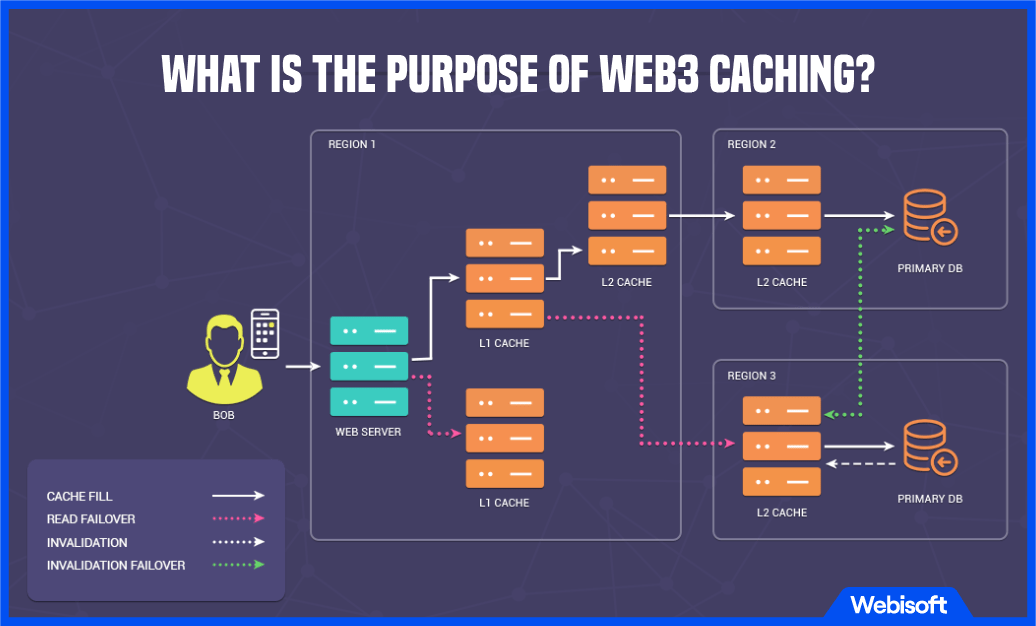
Trying to extract from the blockchain info on transactions for a web3 company for a year? Good luck finding a handy query for that. We’ve got a solution – bring in a web3 cache layer in your design.
Benefits of a Caching Layer in web3
- Get rid of excessive blockchain network queries.
- A speedy data access.
- Craft more intricate queries to the cache layer via any DB – blockchain queries have limits.
- Secure your blockchain data by taking a backup.
- Expose intuitive APIs for smoother data access.
Caching web3: How to Execute It?
Take a peek at our architecture diagram, and you’ll see the caching layer of web3 comfortably housed inside a container. So, let’s break down its components and how they strut their stuff.

Enter the Blockchain Follower
Consider this the wizard microservice that processes blockchain info. How does it stay in sync with blockchain records? We craft a blockchain subscription service.
Here, we employ a listening technique from web3 that tunes into every fresh exchange on the network of blockchain.
let newBlocks = web3.eth.subscribe(‘newBlockHeaders’)
newBlocks.on(‘data’, blockHeader => processBlockHeader(blockHeader, web3Instance));
Voila, we’re now receiving blockchain node data! This raw data, structured in pure blockchain fashion, can be processed and whipped into a better organized format to stash away in the database. What’s more, we can index this data for a quick draw.
But let’s not get ahead of ourselves. While our syncing service is pretty nifty, we must factor in some considerations in the following section to ensure our caching layer is speedy, reliable, and structured.
Database
We’re dealing with incoming blockchain info, and we need a home for it – a database. Here we can structure the data for easy querying. This database is your secret weapon because:
- It allows us to run complex queries to get the results we need.
- We can retrieve aggregated data for showcasing in pretty graphs.
- We can index data based on a DB key to speed up data fetching.
Our preferred tool? PostgreSQL, sometimes referred to as Postgres, is a free of charge, open-source system for managing relational databases that emphasizes flexibility and SQL conformance.
With proper structuring, the blockchain information slips right into the database, ready for querying to meet the needs of web3 products. Plus, indexing and other factors improve query performance. lightning-fast.
Here’s a sneak peek at what the DB structure might look like —
{
blockHash: txData.blockHash || ”,
blockNumber: txData.blockNumber || 0,
hash: txData.hash.toLowerCase() || ”,
from: txData.from.toLowerCase() || ”,
to: txData.to || ”,
gas: txData.gas || ”,
gasPrice: String(txData.gasPrice) || ”,
gasUsed: receipt.gasUsed || 0,
input: txData.input || ”,
nonce: txData.nonce || 0,
transactionIndex: txData.transactionIndex || 0,
value: txData.value || ”,
contractAddress: contractAddress || ”,
cumulativeGasUsed: cumulativeGasUsed || 0,
logs: logs || [],
status: status || false,
timestamp: timestamp || 0,
modifiedOn: Date.now(),
createdOn: Date.now()
}
Memory-Based Data Storing
Alright, let’s break this down. We’re developing a sort of quick-access layer here, something that needs to be zippy. Now, with the web3 setup, we might have bits of data that won’t flip around too often but are still in pretty constant demand on the user’s end. So, where can we put that data? How about a memory-stored database?
Redis is like our knight in shining armor here. This memory-stored data structure doesn’t just act as a shared key-value store, but also as a cache, and notification handler. It has this cool option for durability as well.
So, those bits of data that need to be pulled up often and won’t alter much? They can hang out in Redis. And guess what, fetching them from Redis is a whole lot faster than running an info query.
Accessible APIs
Since we’ve got our quick-access layer up and running, we need a way to make data available to the user’s end from the server. Two ways come to mind for setting up APIs.
The first one is a bit old-school, with various necessary APIs defined and all requests getting a manual check-up. However, there’s a more contemporary and efficient method using GraphQL, which really shines when dealing with large systems like ours.
Now, GraphQL is a free language designed to work with APIs, especially for data querying and manipulation. It’s like a sort of runtime, helping us execute queries with the data we already have.
Instead of having a bunch of API endpoints out in the open, we could use GraphQL, allowing us to connect with our quick-access layer’s database just as we want.
Real-Time Connections
Imagine a scenario where a user is browsing the web3 item page, while in the shadows, a deal goes through that boosts their balance. Is it fantastic if the user’s balance is updated in real-time, without needing a page refresh?
This way, the user gets to experience a truly live and synchronized state of the shared ledger. Sounds like magic? Well, Socket.IO can make it happen.
Socket.IO is a library that thrives on events and is great for live web apps. It sets up a two-way communication line between the user and the server, as live as it gets.
This implies that any blockchain update can get to users quickly. Thus, the user has the impression that they are receiving real-time data via the blockchain.
B2B APIs
Aside from APIs, graphQL the web3 cache can provide access to various B2B APIs. Unlike the helpful graphQL, these may be made public and built for specific activities. These APIs are preset, meaning they cannot query data directly from the database.
Instead, they adhere to a certain business strategy. These APIs are designed to meet business needs, and our gleaming new cache tier is their super companion, making B2B API answers faster than typical web3 queries to the blockchain.
How Do You Secure Reliability in the Caches Layer of Web3 Products?
Security should be a top priority for all connections and APIs exposed through our caching layer. How can we bolster the security of our web3 caching layer? Here are a couple of ways:

Meet the API Gateway
Think of an API gateway as the bouncer for your organization’s access point. It flexes its security muscles with access control and encryption that meet industry standards. The creme de la creme of API gateways is designed to offer robust security.
Here’s a quick rundown of the tasks they’re typically entrusted with:
- Acts as the gatekeeper for API control.
- Verifies API requests using credential and token authentication.
- Decides which traffic gets the green light to the API’s backend services.
- Regulates API traffic through rate throttling or limiting.
- Logs all activities and applies runtime policies for governance.
- Offers final-mile protection for the backend systems running the APIs.
Get Familiar with JWT Authentication
Security is essential when it involves protecting your web assets. One option to strengthen your defenses is to use JSON online Tokens (JWT) in online apps. JWT is a free protocol that enables two parties to securely exchange data.
Furthermore, JWTs have the extra benefit of providing agnostic management of sessions (goodbye session cookies!). This implies your backend server will not need to communicate with an authorization server.
And the icing on the cake? JWT works well with all sorts of ledgers, and you can set up as many JWTs as you like on a distributed ledger.
Session Validation (when needed)
There are several methods for managing user sessions. You can keep them directly on the server that replied to the demand, and build a layer into the design to safely and scalably keep those sessions.
Many app designs include libraries to facilitate incorporation and store visits in memory, thus sessions may be kept in key/value storage. You may also write custom session controllers to maintain the session running.
Wrapping Up
A web3 cache is a big deal for the business side of web3 products. It cuts down the amount of back-and-forth needed to fetch and serve up content, which can seriously improve network usage.
It also means there’s less need to set up repeat infrastructure. The result? Major savings, both financial and energy-wise, for the whole internet ecosystem. Large-scale business caching providers can take it a step further by using a massive infrastructure that multiple customers can share.Are you ready to make your vision a reality? Welcome to Webisoft, where we specialize in cross-platform apps, whether it’s Web3, Blockchain, Mobile, or SaaS! Our expert team turns complex concepts into user-friendly applications. Reach out to us today!
